
![By Razvan Orendovici from United States (Pattee Library Catalogs) [CC BY 2.0 (http://creativecommons.org/licenses/by/2.0)], via Wikimedia Commons](https://lafacette.files.wordpress.com/2015/03/512px-2010_4559410051_card_catalog.jpg)
By Razvan Orendovici from United States (Pattee Library Catalogs) [CC BY 2.0 (http://creativecommons.org/licenses/by/2.0)%5D, via Wikimedia Commons
RIMMF veut dire « RDA in Many Metadata Formats », ce que je traduirais par « RDA dans de multiples formats de métadonnées ».
Le RIMMF est en fait une application qui permet de s’entraîner au catalogage en RDA, et donc à la manipulation du modèle FRBR, sans être assujetti au format MARC. Cerise sur le gâteau, il permet une visualisation de ces données de catalogage dans un contexte web de données. Autrement dit, avec le RIMMF on va créer des données ET chercher à les intégrer dans un environnement Web plus large.
Si on en croit de nombreux retours de stagiaires, les formations dispensées en France dans le cadre du groupe national pour la transition bibliographique sont souvent jugées trop théoriques. Il faudrait pouvoir pratiquer pour comprendre.
Devrions-nous RIMMFer nous aussi ?
J’ai voulu tester l’outil pour voir s’il valait le coup de s’y intéresser plus sérieusement et si nous pourrions nous en servir dans le cadre d’ateliers en France, avec l’idée que ça pourrait être utile pour bien comprendre le modèle FRBR, la structure du code de catalogage RDA, et le lien avec le web de données.
Même si, rappelons-le, nous avons préféré en France une transition bibliographique douce à un changement radical pour RDA.
Au sommaire :
- Eléments de vocabulaire pour comprendre le RIMMF
- De quoi a-t-on besoin pour RIMMFer aujourd’hui ?
- Test rapide
- Utiliser le RIMMF en France ?
- Conclusion
- Sources
Eléments de vocabulaire pour comprendre le RIMMF
Le RIMMF s’avère particulièrement utile dans le cadre d’un Jane-athon, où l’on part d’une r-ball basique pour créer une grosse r-ball de la mort pleine de linked data. Valà.
Partez pas, j’explique (mais brièvement).
 RIMMF = RDA in Many Metadata Formats. Application d’entraînement au catalogage en RDA et de visualisation du modèle FRBR dans un contexte web de données. Ce n’est qu’un outil d'(auto)formation, il ne peut servir à cataloguer réellement dans un SIGB.
RIMMF = RDA in Many Metadata Formats. Application d’entraînement au catalogage en RDA et de visualisation du modèle FRBR dans un contexte web de données. Ce n’est qu’un outil d'(auto)formation, il ne peut servir à cataloguer réellement dans un SIGB.
L’idée est de saisir les descriptions dans un formulaire simple, en langage courant, qui permettra l’export en de multiples formats (RDF, XML, MARC…).
Le RIMMF a été développé par la société The MARC of Quality (TMQ) et mis à disposition du public dès janvier 2012. Il en est à sa 3ème version (RIMMF3).
FRBR = Functional Requirements for Bibliographic Records = Spécifications fonctionnelles des notices bibliographiques : modèle conceptuel de données bibliographiques.
On distingue aujourd’hui les FRBRer (FRBR en mode entité-relation) et FRBRoo (FRBR orienté objet).
FRBRer (FRBR entité-relations) propose d’organiser l’information bibliographique selon 4 aspects :
- œuvres (work en anglais),
- les expressions (expression),
- les manifestations (manifestation),
- les items (item).
Nos notices actuelles dans WinIBW comportent principalement des éléments de Manifestation (ce titre a été édité chez PUF en 2010), des éléments d’Item (localisé dans la bibliothèque X à la cote XXX) mais aussi des éléments d’Oeuvre (lien vers l’autorité auteur/titre ou le titre uniforme) et d’Expression (le livre est en français, traduit de l’anglais).
Oeuvre, expression, manifestation et item sont des entités du groupe 1 et s’articulent avec des entités du même groupe ou de 2 autres groupes :
- le groupe 2, dont les règles sont explicitées dans les FRAD (Functional Requirements for Authority Data), concerne les autorités relatives à la responsabilité intellectuelle et artistique ;
- le groupe 3, modélisé dans les FRSAD (Functional Requirements for Subject Authority Data), concerne les sujets.
On peut ainsi établir des relations riches et complexes entre entités de différents groupes (une oeuvre avec son créateur, une manifestation avec son éditeur, un roman avec son adaptation cinématographique, un jeu de carte dérivé d’une pièce de théâtre, la traduction d’un manuscrit dans une autre langue, etc.).
Chaque entité est décrite par des attributs (titre, date, nom de personne, etc.).
RDA = Resource Description and Access. Code de catalogage développé par le Joint Steering Committee dans l’intention de remplacer les règles de catalogage anglo-saxonnes AACR2 par un code plus orienté Web. RDA se base sur le modèle FRBR (FRBRer pour être précis) et réutilise sa terminologie (modèle entité-relations, attributs…). Le code RDA est accessible sur abonnement payant et s’appelle le RDA Toolkit. Le RDA Toolkit ne se suffit pas à lui-même, ses préconisations doivent être complétées par l’élaboration d’un profil (un peu comme on se base sur l’ISBD, dont on précise l’application par les normes de catalogage Afnor, sur lesquelles on se base pour coller à nos besoins BU dans le guide méthodologique).

Diapo issue d’une présentation ABES http://pt.slideshare.net/abesweb/idref-as-a-shared-service
Web de données (linked data) : ensemble de standards et technologies permettant d’exposer sur le Web et de lier entre elle des données structurées tout en facilitant leur interopérabilité. Si vous avez de bonnes bases et que vous voulez acquérir une expertise en la matière, un MOOC vient de commencer sur FUN cette semaine, foncez !
R-Ball : agrégats de données ou de notices permettant au final une représentation dans le web de données de ressources décrites en RDA. Ces données peuvent ainsi être représentées sous forme de graphe RDF. La r-ball est créée et maintenue avec le RIMMF et sert de base à un Jane-athon. On peut télécharger les r-balls de base pour les intégrer au RIMMF, et c’est parti Kiki.

« Jane Austen Semper » by Eymery – Own work. Licensed under CC BY-SA 3.0 via Wikimedia Commons – http://commons.wikimedia.org/wiki/File:Jane_Austen_Semper.jpg
Jane-athon : hackathon, ou atelier collaboratif partant de Jane Austen et utilisant le RIMMF pour produire et agencer des métadonnées en s’appuyant sur le code RDA.
On part d’une r-ball de base contenant l’identifiant de l’auteur, des oeuvres en relations, et on construit une r-ball beaucoup plus touffue en ajoutant des éléments conformes à RDA à l’aide du RIMMF. En langage web de données, on peut dire qu’on part d’un petit graphe pour aboutir à un gros graphe. Vous suivez ?
Un prototype Jane-athon a été testé à Hawai en décembre 2014 pour être reconduit lors du congrès de l’American Library Association en janvier dernier. Le RIMMF est alors revenu sur le devant de la scène dans les réseaux sociaux, d’où mon regain d’intérêt.
Voir la présentation de Diane Hillman (en anglais) pour accompagner un Jane-athon.
De quoi a-t-on besoin pour RIMMFer aujourd’hui ?
- télécharger l’application sur son PC. Attention pour les Unix-fans, le RIMMF3 ne fonctionne que sous Windows… ;
- maîtriser un minimum l’anglais, notamment l’anglais professionnel : il n’existe pas actuellement de version française de l’outil ;
- connaître le modèle FRBR, avoir de bonnes notions du fonctionnement du code RDA (autrement dit : avoir suivi la journée de sensibilisation à l’évolution des catalogues) ;
- une connexion internet est préférable, même s’il est semble-t-il possible de travailler hors ligne
- l’accès au RDA Toolkit – par exemple moi, je n’y ai pas accès. C’est payant, et genre cher. Il faudrait voir dans quelle mesure l’accès pourrait être ouvert aux formateurs et aux stagiaires dans le cadre des formations nationales.
Test rapide
J’ai à plusieurs occasions montré en formation des extraits d’une vidéo (en anglais) de la société VTLS, qui présentait un mode de catalogage FRBRisé. J’avais également jeté un oeil au BIBFRAME editor qui permet de tester le catalogage « à niveau » : oeuvre, expression, manifestation, et item, sans s’inquiéter du MARC. Même principe ici.
Je suis très loin d’avoir vu/testé toutes les fonctionnalités du RIMMF et je ne suis pas allée jusqu’à charger des lots de données pour visualiser les relations entre différentes entités, différentes ressources, et les autorités afférentes.
On peut voir des copies d’écran très intéressantes dans cette présentation récente d’Alan Danskin (en anglais).
A titre individuel, on peut s’entraîner en mode WEM (Work-Expression-Manifestation) à compléter une notice de manifestation (je prends un livre à cataloguer et je le décris comme je le ferais dans WinIBW), puis je complète la notice d’oeuvre puis celle d’expression.
Des tutoriels (en anglais) sont proposés sur le Wiki du RIMMF3.
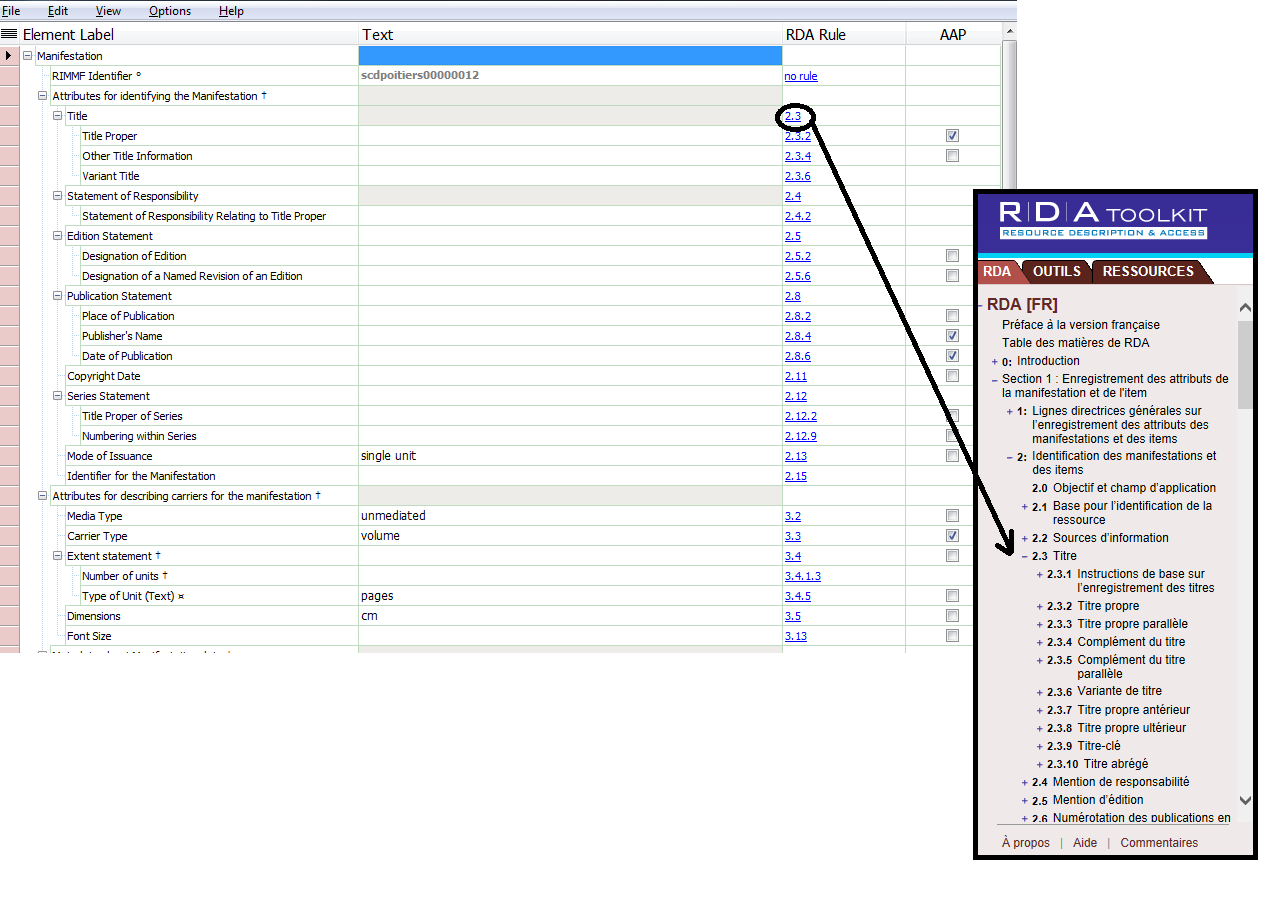
Pour jeter un oeil à une grille de catalogage : ouvrir File \ New record for… \ Manifestations \ manifestation Template TMQ.Book.Pub.Core.Simple.txt

Une grille à compléter s’ouvre dans laquelle on voit 4 colonnes :
- Element label = intitulé du champs ;
- Text = élément de description à compléter par le catalogueur ;
- RDA Rule = lien vers le chapitre concerné dans le RDA Toolkit – comme je le disais, je n’y ai moi-même pas accès ;
- AAP = Authorized Access Point = point d’accès autorisé.

Utiliser le RIMMF en France ?
Peut-on dupliquer le RIMMF pour en faire une version française ?
A priori non. Le RIMMF est placé sous licence CC BY-NC-SA, ce qui nous autorise à l’utiliser en formation (demander une autorisation aux auteurs si on est rémunéré), diffuser des copies d’écran (en citant la source), reprendre son contenu. En revanche, comme nous l’apprend la FAQ du Wiki dédié au RIMMF, le code-source n’est pas disponible, lui, car il comporte des composants commerciaux qui ne peuvent être publiés.
C’est d’ailleurs clairement indiqué au moment où on installe le logiciel :
 Cela dit, si le groupe national « formation » trouve la piste intéressante, il me paraît possible de prendre contact avec les développeurs du RIMMF pour voir s’ils accepteraient de travailler conjointement à une version francophone. J’entends par là une version avec un texte traduit, pas une version adaptée aux règles de catalogage française (faut peut-être pas pousser Mémé…).
Cela dit, si le groupe national « formation » trouve la piste intéressante, il me paraît possible de prendre contact avec les développeurs du RIMMF pour voir s’ils accepteraient de travailler conjointement à une version francophone. J’entends par là une version avec un texte traduit, pas une version adaptée aux règles de catalogage française (faut peut-être pas pousser Mémé…).
[Edit 08/03/2015. En fait si, plus je réfléchis à comment s’exercer et intégrer les nouvelles normes de catalogage, plus je me dis que le RIMMF serait parfait. Faudrait essayer de pousser Mémé et demander à remplacer les liens pointant vers le RDA Toolkit par d’autres pointant vers nos nouvelles règles, ou mieux, ajouter une colonne RDA-FR]
Peut-on utiliser le RIMMF si l’on n’a pas accès au RDA Toolkit ?
On perd évidemment l’intérêt d’utiliser le RIMMF pour mieux comprendre comment fonctionne RDA et sur quelle partie du code tel ou tel élément s’appuie. Ce serait comme s’entraîner sur WinIBW sans accès au guide méthodologique.
D’un autre côté, ce n’est peut-être pas plus mal que les stagiaires français ne s’entraînent pas sur le RDA Toolkit, puisque nous n’en appliquons pas les préconisations à la lettre.
D’autre part, le RIMMF dans le cadre d’un Jane-athon a pour objectif de montrer la modélisation des données telle qu’entendue par RDA, et pas d’étudier en détail le code de catalogage.
Dans l’idéal, il nous faudrait une version française qui irait piocher dans les parties de la norme Afnor révisées. Ces chapitres, réécrits à la lumière de RDA et de l’ISBD intégré, seront mis en ligne gratuitement au fur et à mesure qu’ils seront validés. Dans l’encore plus idéal, on pourrait imaginer une version Sudoc, qui s’enrichirait d’une colonne « Guide méthodologique ». Mais là on est serait presque dans un prototype d’interface de catalogage Sudoc 2…
Organiser un French Jane-athon ?
![By Berlin-George (Own work) [CC BY-SA 3.0 (http://creativecommons.org/licenses/by-sa/3.0)], via Wikimedia Commons](https://lafacette.files.wordpress.com/2015/03/france_5_francs_1959-_vf-_banknote_obverse.jpg)
By Berlin-George (Own work) [CC BY-SA 3.0 (http://creativecommons.org/licenses/by-sa/3.0)%5D, via Wikimedia Commons
Un peu comme si on refaisait data.bnf à la main le temps d’une journée.
L’avantage de Jane Austen, c’est qu’il existe aussi un jeu de plateau, un magazine de tricot et une version bande dessinée d’Orgueil et Préjugés. [Edit : je viens de voir passer ce tweet sur la version manga].
Tout ça à cataloguer, miam.
Mais on doit pouvoir s’éclater avec un tas de produits dérivés pour un Victor-athon, surtout autour des Misérables ou de Notre-Dame de Paris.
Le RIMMF reste néanmoins indispensable pour permettre une simulation de traitement des métadonnées en situation réelle.
Des exercices pratiques de FRBRisation sur papier, de nombreux formateurs en proposent déjà, mais à ma connaissance aucun ne propose de mise en situation réelle. La formation à distance animée par Julien Béal pour l’ENSSIB offre un modèle de formation plus intéractive, mais ne va pas jusqu’à simuler une interface de catalogage pour mise en pratique « de terrain », il me semble.
Je ne connais par ailleurs aucun outil utilisable par un non-informaticien pour patouiller dans le triptyque création de données bibliographiques / liens vers l’extérieur / visualisation dans un environnement Web de données. Si vous avez des pistes, je suis preneuse en commentaire !
D’un autre côté, nous n’échapperons pas à l’habituelle frustration : j’ai compris, c’est chouette, mais concrètement quand je retourne à mon bureau, j’en fais quoi ?
Je crains que la réponse ne demeure : j’attends. J’attends le Sgbm, j’attends Sudoc 2, j’attends les prochaines vagues de consigne de l’Abes… Je ne sais pas ce qu’un catalogueur peut faire au quotidien de ces connaissances et de cette expérience.
Le Jane-athon ne focalise pas sur le catalogage lui-même et se veut un moment de rencontre et d’échanges entre personnes qui s’intéressent au Web de données sous différents aspects : catalogueurs mais aussi administrateurs Sigb, informaticiens… Dans cette optique-là, et dans une période de mutation des métiers et des pratiques, ça vaudrait peut-être le coup.
Pourquoi pas un premier Victor-athon test pour que le groupe national de formateurs se fasse la main ? Et un Victor-athon pour préparer Sudoc 2 ?
Conclusion
Tel quel, il me paraît difficile d’utiliser le RIMMF en auto-formation ou dans le cadre de nos formations. L’anglais, pour commencer, pourrait poser problème à un certain nombre de candidats.
L’un des intérêt du RIMMF, perdu pour nous, est la possibilité de cliquer sur les liens pour consulter le RDA Toolkit. L’équivalent de notre F1 dans WinIBW quand on a besoin d’accéder au Guide méthodologique.
D’un autre côté, cet accès n’aurait qu’un intérêt tout relatif, puisque nous n’adoptons pas RDA en l’état. Dans nos pratiques courantes Sudoc, les attributs relevant de telle ou telle entité sont introduits petit à petit, sous forme de « vagues de consignes » pour le catalogage dans WinIBW. Nous devrions surfer sur la seconde vague avant l’automne.
[Edit 08/03/2015 : j’ajoute que si on pouvait collaborer avec les auteurs du RIMMF pour développer une version FR, avec textes en français et colonne supplémentaire permettant l’accès à nos nouvelles normes de catalogage RDA-FR, alors là c’est une autre histoire. Plus je cherche comment transmettre et faire intégrer les nouvelles normes, plus je me dis que, décidément, le RIMMF serait idéal.]
Il me semble néanmoins que le RIMMF, utilisé dans le cadre d’un Jane-athon, va plus loin, et surtout ne met pas l’accent sur le catalogage en lui-même. A partir d’une petite r-ball, un premier groupe de données, on va pouvoir construire, lier, associer, jusqu’à obtenir une r-ball géante avec des oeuvres en relation, des liens vers des autorités, etc. et visualiser tout cela dans différents formats.
Un atelier de ce type permettrait aux participants de mieux appréhender l’étendue du maillage que l’on peut obtenir à partir d’un auteur et la place que peuvent occuper les bibliothèques en tant qu’acteur du Web.
Nous en montrons le résultat avec data.bnf, mais nous ne fournissons pas encore l’occasion de mettre réellement la main à la pâte.
Le RIMMF offre donc la possibilité de tester un catalogage FRBRisé sur une interface en langage courant (au lieu de l’Unimarc), et de mieux concevoir l’interrelation FRBR / RDA / web de données dont on entend si souvent parler sans toujours percevoir ce que ça veut dire.
Ce n’est tout de même pas rien et ça vaudrait peut-être le coup de creuser un peu plus.
[Edit 28/08/2015 : je découvre que la BNE s’intéresse de près au RIMMF depuis 2012 et a participé au Janeathon de l’ALA cette année…]
Sources
Pour les informations et copies d’écran provenant de l’application RIMMF3 elle-même, je reprends ici les termes exacts de la licence :
RIMMF, ©2012 Deborah Fritz, Richard Fritz (http://www.marcofquality.com/rimmf)
Used under a CC BY-NC-ND 3.0 license (http://creativecommons.org/licenses/by-nc-nd/3.0/).
Screen image from RIMMF software (http://www.marcofquality.com/rimmf) used by permission of the copyright holders (Deborah Fritz and Richard Fritz).
Webographie RIMMF
Je me mets parallèlement un peu plus sérieusement à Zotero, parce que jusqu’ici j’ai eu la flemme de l’introduire dans mes pratiques courantes – à tort : bon sang que c’est utile et facile à utiliser !
Du coup, je gratifie ce billet d’une vraie bibliographie structurée, youhou.
- DANSKIN, Alan, 2015. FRBR unMARCed : RDA cataloguing with RIMMF. In : [en ligne]. CIG Linked data, Imperial College. février 2015. [Consulté le 5 mars 2015]. Disponible à l’adresse : http://www.cilip.org.uk/cataloguing-indexing-group/presentations/linked-data-what-cataloguers-need-know-2015.
- DUNSIRE, Gordon, HILLMANN, Diane, PHIPPS, Jon, FRITZ, Deborah et FRITZ, Richard, [sans date]. R-balls. In : R-balls [en ligne]. [Consulté le 24 février 2015]. Disponible à l’adresse : http://rballs.info/.
-
FRITZ, Deborah et FRITZ, Richard, [sans date]. RIMMF3 Home. In : The MARC of quality [en ligne]. [Consulté le 17 février 2015]. Disponible à l’adresse : http://www.marcofquality.com/wiki/rimmf3/doku.php.
-
HENNELLY, James, 2014. Fun with Dick and Jane (and RDA): Creating linked data for Jane Austen and Blade Runner. In : RDA Toolkit [en ligne]. 13 octobre 2014. [Consulté le 17 février 2015]. Disponible à l’adresse : http://www.rdatoolkit.org/janeathon.
-
HILLMANN, Diane, 2014. The Jane-athon Prototype in Hawaii. In : Metadata Matters [en ligne]. décembre 2014. [Consulté le 17 février 2015]. Disponible à l’adresse : http://managemetadata.com/blog/2014/12/19/the-jane-athon-prototype-in-hawaii/.
- HILLMANN, Diane, 2014. What’s this Jane-athon thing? In : Metadata Matters [en ligne]. 27 octobre 2014. [Consulté le 5 mars 2015]. Disponible à l’adresse : http://managemetadata.com/blog/2014/10/27/whats-this-jane-athon-thing/.
-
HILLMANN, Diane, 2015. The Jane-athon Report. In : Metadata Matters [en ligne]. février 2015. [Consulté le 17 février 2015]. Disponible à l’adresse : http://managemetadata.com/blog/2015/02/14/the-jane-athon-report/.
-
JOINT STEERING COMMITTEE FOR DEVELOPMENT OF RDA, 2015. Jane-athon success. In : JSC RDA [en ligne]. février 2015. [Consulté le 23 février 2015]. Disponible à l’adresse : http://www.rda-jsc.org/Jane-athon.html.
-
LAM, Henry, 2013. 5 minutes reading : RIMMF. In : Silas [en ligne]. 11 octobre 2013. [Consulté le 17 février 2015]. Disponible à l’adresse : https://www.silas.org.sg/ReadingRoom/5minutesreading/tabid/121/entryid/110/RIMMF.aspx.
-
TALLEY, Jennifer, 2015. #janeathon : Come RIMMF our R-balls! In : Storify [en ligne]. février 2015. [Consulté le 17 février 2015]. Disponible à l’adresse : https://storify.com/jenunexpected/janeathon.
-
TMQINC, 2013. RIMMF Notes. In : RIMMF Notes [en ligne]. février 2013. [Consulté le 24 février 2015]. Disponible à l’adresse : https://rimmf.wordpress.com/.
- WILLIAMS, Elliot, 2014. Exploring RDA with RIMMF. In : Elliot Williams [en ligne]. décembre 2014. [Consulté le 3 mars 2015]. Disponible à l’adresse : http://www.elliotdwilliams.com/rda-in-many-metadata-formats/.

{kind=link}
Pingback: RIMMFons gaiement | Vers le Web sémantiq...
Pingback: RIMMFons gaiement | BiblioThec[a] aperta | Sco...
Je repose ma question ici, en développant un peu.
Supposons que je veuille développer, là maintenant, un prototype de RIMMF-fr. A quelles règles de catalogage mon application devrait-elle se référer pour faire des liens comme dans le RIMMF original ? Ces règles sont-elles disponibles librement, et où ?
(Parce qu’en fait, ça me plaît bien ce concept de RIMMF, et j’ai un vague embryon d’idée derrière la tête.)
J’aimeJ’aime
J’aime bien les vagues embryons d’idées! 🙂
Alors, si on voulait développer un RIMMF-fr là tout de suite, il faudrait pour le moment continuer à s’appuyer sur les normes Afnor. Qui ne sont pas disponibles gratuitement en ligne. Exit donc le lien vers la norme dans un premier temps.
Faire des liens vers le guide méthodo, ça impliquerait que notre RIMMF-fr soit en fait un RIMMF-Sudoc. On ferait alors correspondre des champs Unimarc aux intitulés courants du RIMMF, puisque c’est comme ça qu’est organisé le GM pour l’aide au catalogage par champs. L’outil serait moins résolument agnostique aux formats.
Si on voulait développer le RIMMF-fr, ce serait pour moi dans une perspective à moyen et long terme, pour accompagner la publication des normes Afnor révisées en RDA-fr.
Les premiers chapitres modifiés seront publiés en ligne et disponibles gratuitement prochainement (au printemps?) et une campagne nationale de formation est envisagée pour l’automne.
C’est dans la perspective de ces formations qu’il me semblait intéressant de se pencher sur le RIMMF. Les normes Afnor classiques et les chapitres modifiés de RDA-fr vont cohabiter pendant un bon moment, nous aurions donc un outil qui proposerait le lien vers le chapitre RDA-fr lorsqu’il existe, et la référence de la norme Afnor lorsqu’elle n’a pas été révisée. La proportion Afnor / RDA-fr étant vouée à s’inverser au fur et à mesure que les chapires RDA-fr seront publiés.
Alors, c’est quoi cet embryon d’idée? 😉
J’aimeJ’aime
Merci pour toutes ces précisions.
Je vais creuser un peu en installant RIMMF, même si ça implique de toucher à Windows (c’est dire l’intensité de mon intérêt pour RIMMF 🙂 ). Cataloguer sans se préoccuper du format, c’est une sorte d’idéal professionnel pour moi…
J’aimeAimé par 1 personne
Pour ceux qui seraient intéressés, l’installation de RIMMF sur debian, en utilisant wine, fonctionne très bien. Du coup, j’ai pu jouer un peu et télécharger les r-balls pour newbies.
Pour l’instant, je ne vois pas bien comment on pourrait l’adapter à l’usage français. Par exemple, lorsqu’on crée un « New Record for Work », on trouve un champ Title qui fait référence au paragraphe 6.2 de RDA : « Title of the work » (de la section 6, « Identifying Works and Expressions »).
Nos normes AFNOR proposeront-elles quelque chose de semblable ? Sera-t-il explicitement question de la description des Oeuvres et Expressions (par exemple) ?
Désolé pour la naïveté de ces questions, mais j’essaie de bien comprendre tout ça et je patauge un peu. En tout cas, merci de m’avoir fait découvrir RIMMF 🙂
J’aimeJ’aime
Cool, continue à nous faire partager tes expériences !
Alors oui, à terme on a bien pour objectif de produire des catalogues FRBRisés, c’est aussi un peu (beaucoup) pour ça qu’on implémente RDA. Je ne suis pas la mieux placée pour répondre à tout ça, mais à ma connaissance l’ABES planche sur l’implémentation de nouveaux champs Unimarc pour gérer les niveau oeuvre / expression, c’est évoqué dans rda.abes.fr notamment là http://rda.abes.fr/2012/12/19/mais-quest-ce-quil-se-passe-3-sudoc/ (mais ça date de 2012…).
Les normes RDA-FR se basent principalement sur RDA (c’est pour ça qu’on les appelle RDA-FR, d’ailleurs), donc vont intégrer les notions d’oeuvre, d’expression, et les règles qui vont avec.
Si tu n’as pas eu l’occasion de suivre la « journée de sensibilisation à l’évolution des catalogues et des formats de catalogage », c’est ce qu’il te manque pour poursuivre sur de bonnes bases! 😉
J’aimeJ’aime
Pingback: RIMMFons gaiement | Numériques | Scoop.it
Pingback: Catalogage | Pearltrees